白衣少年wst 发表于 2025-7-29 08:35
如果是按照这个,那平均值、标准差还有临界值又是怎么来呢?
 173.84cm,176.96cm)
173.84cm,176.96cm)zxb6668 发表于 2025-07-29 11:30
其实很简单,其本质还是用样本来估计总体的一种区间估计。“”白衣少年wst“”已经举例讲的很清楚啦。
“”点估计+置信度范围“”=置信区间(CI)
假设我们想估计某地区成年男性的平均身高(总体均值)。我们抽取了一个包含 100 名男性的随机样本,计算出样本平均身高x-=175 cm,样本标准差s*10 c。我们想要一个 95%的置信区间。
1.点估计:x=175 cm
2.选择临界值: 由于样本量较大(n=100>30),我们使用标准正态分布(z分布)。95% 置信度对应的 z* 临界值是 1.96。
3.计算标准误:标准误(SE)=s/in=10/100=10/10 =1 cm4.计算误差范围:误差范围(ME)=z**SE=1.96*1-1.96cm5.构造置信区间:
下限:x-ME=175-1.96=173.04 cmD
。 上限:x+ME=175+1.96=176.96 cm
。95%置信区间173.84cm,176.96cm)
微信d6ss82z3 发表于 2025-07-29 08:52
(1)先按质量标准计算方式求出检测结果。(2)使用EXCEL计算置信区间:①先利用EXCEL求出样本平均值AVERAGE,②求出标准误差:公式STDEV.S(样本检测结果列)/SQRT(COUNT(样本检测结果列))③求出临界值:公式T.INV.2T(1-置信水平,自由度=样本量-1),一般取置信水平99%或95%。④CL:置信下限:样本平均值-(标准误差×临界值);CU:置信上限:样本平均值+(标准误差×临界值)
世间始终你好 发表于 2025-07-29 08:45
2025年版《中国药典》四部(特别是附录)关于分析方法验证中的置信区间(Confidence Interval, CI),主要涉及到准确度(accuracy)、线性(linearity)、效价测定(特别是量反应关系)、以及稳定性研究等方面。在附录通则如**通则9101《分析方法验证》及3.3《量反应关系测定法(平行线法)》**中都有所体现。
你问的是置信区间怎么计算、怎么取,以下是详细解答。
一、常见场景中“置信区间”的作用和计算场景1:线性验证中的置信区间(用于线性回归)目的:验证分析方法在给定浓度范围内的线性相关性。
1. 用最小二乘法拟合线性方程:y=a+bxy = a + bx其中,y 为响应值,x 为已知浓度,a 为截距,b 为斜率。
2. 置信区间的计算(95%CI)对于斜率 bb 和 截距 aa:
CIb=b±t(n−2,0.975)⋅SEbCI_b = b \pm t_{(n-2, 0.975)} \cdot SE_bCIa=a±t(n−2,0.975)⋅SEaCI_a = a \pm t_{(n-2, 0.975)} \cdot SE_a其中:
SEbSE_b、SEaSE_a 是标准误差,由回归分析计算;
t(n−2,0.975)t_{(n-2, 0.975)} 为 t 分布临界值(自由度 = 样本数 − 2);
95% 表示置信水平。
3. 如何判断线性“通过”?药典推荐:
R2≥0.99R^2 \geq 0.99;
斜率的 95%CI 不应包含 0;
预测区间不能超出可接受范围(如响应值偏差在 ±15% 内);
场景2:效价测定(平行线法)中的置信区间目的:用于报告效价点估计值的置信区间,说明该测定方法的统计可靠性。
药典(2025版3.3节)中提供的算法本质上是基于方差分析(ANOVA)后的斜率估计,常见表达为:
CI=效价⋅exp⁡(±t⋅V)CI = \text{效价} \cdot \exp\left( \pm t \cdot \sqrt{V} \right)其中:
VV:效价对数的方差;
tt:置信水平为 95% 时,对应自由度下的 t 值;
置信区间是“对数对称”的。
举例:
若效价为 100 IU/mL,对应 V = 0.01,自由度为 4:
CI=100⋅exp⁡(±2.776⋅0.01)=100⋅exp⁡(±0.2776)⇒CI≈(75.7,132.2)CI = 100 \cdot \exp( \pm 2.776 \cdot \sqrt{0.01} ) = 100 \cdot \exp( \pm 0.2776 )\Rightarrow CI \approx (75.7, 132.2)这是一种 log-normal 表达方式。
场景3:准确度验证中(回收率)置信区间目的是:评估样品回收率是否在预设接受范围内(如 98%-102%)
计算方法:CI=xˉ±t⋅snCI = \bar{x} \pm t \cdot \frac{s}{\sqrt{n}}其中:
xˉ\bar{x}:平均回收率;
ss:标准差;
nn:样本数量;
tt:t分布临界值。
例如:
平均回收率为 99.5%,标准差为 1%,n=6:
CI=99.5±2.571⋅16≈99.5±1.05⇒(98.45,100.55)CI = 99.5 \pm 2.571 \cdot \frac{1}{\sqrt{6}} \approx 99.5 \pm 1.05 \Rightarrow (98.45, 100.55)如果 CI 完全落在 98%-102% 内,则准确度验证通过。
二、药典中没有明确公式的情况如何处理?对于没有直接公式的情况,如批间一致性、耐用性验证等,也可以采用上面类似的置信区间计算方式,只要样本服从正态分布或可近似处理为正态分布(中心极限定理支持),都可以采用 t 分布推导置信区间。
三、总结——怎么“取”置信区间?场景置信水平方法说明
线性回归通常95%回归参数 ± t·SE判断斜率与截距显著性
准确度验证通常95%平均值 ± t·(s/√n)置信区间是否落入接受范围
效价测定(平行线法)通常95%CI = 点估值·exp(±t·√V)药典指定方式
重复性/中间精密度通常95%标准差 ± t·(s/√n)可辅助分析方法鲁棒性
白衣少年wst 发表于 2025-7-29 12:39
是否可以理解为,我准确度制备了6份样品,测得6个回收率,然后用这6个回收率计算平均值和标准差,要Excel ...
“我准确度制备了6份样品,测得6个回收率,然后用这6个回收率计算平均值和标准差,要Excel表进行正态分布,得出临界值,然后假设我们取的置信度为98%,然后再计算区间。”可以细化为如下步骤:
| 项目 | 内容 |
| 置信度选择 | 药典常用 95%,你可以根据需要选 98%/99% |
| t值获取方式 | Excel函数:=T.INV.2T(1-置信度, 自由度) |
| 标准差用法 | 注意使用 STDEV.S()(样本标准差) |
| 样本量越大 | CI 越窄,更具代表性 |
| 是否正态分布? | 正态分布假设通常默认成立,n≥6时基本接受 |
| 检查通过标准 | CI 是否全部落在设定接受范围内(如98%–102%) |
白衣少年wst 发表于 2025-7-29 12:38
是否可以理解为,我准确度制备了6份样品,测得6个回收率,然后用这6个回收率计算平均值和标准差,要Excel ...
微信d6ss82z3 发表于 2025-07-29 15:01
推荐2025年版药典四部通则9097 分析数据的解释与处理指导原则学习置信区间和预测区间的计算
世间始终你好 发表于 2025-07-29 13:00
本帖最后由 世间始终你好 于 2025-7-29 13:01 编辑
是的,你的理解基本正确,我们来逐步确认并稍加补充,让你更准确地掌握分析方法验证中准确度的置信区间计算方法:
你的原始理解流程:“我准确度制备了6份样品,测得6个回收率,然后用这6个回收率计算平均值和标准差,要Excel表进行正态分布,得出临界值,然后假设我们取的置信度为98%,然后再计算区间。”
可以细化为如下步骤:
步骤一:计算样本均值与标准差设你测得的6个回收率为:
98.5%、99.2%、100.1%、100.4%、99.7%、100.2%在 Excel 中可使用:
=AVERAGE(A1:A6) → 平均值 xˉ\bar{x}=STDEV.S(A1:A6) → 标准差 ss
步骤二:确定自由度与置信系数(t值)样本数 n=6n = 6自由度 df=n−1=5df = n - 1 = 5置信度 98%,对应单侧为 0.99,双侧为 0.01/2 = 0.005
查 t 分布表或用 Excel:
=T.INV.2T(1-0.98,5) → 得出 t ≈ 3.365 步骤三:计算置信区间(95%、98%、99%都可)置信区间公式为:
CI=xˉ±t⋅snCI = \bar{x} \pm t \cdot \frac{s}{\sqrt{n}}Excel 中写成:
=平均值 ± t值 * (标准差 / SQRT(n))举例:
平均值:99.68%标准差:0.68%t(98%,自由度5):3.365置信区间宽度:
Δ=3.365⋅0.686≈0.93%\Delta = 3.365 \cdot \frac{0.68}{\sqrt{6}} \approx 0.93\%最终置信区间:
CI=99.68±0.93⇒(98.75CI = 99.68 \pm 0.93 \Rightarrow (98.75%, 100.61%) 总结:你要记住的关键点[td]项目内容置信度选择药典常用 95%,你可以根据需要选 98%/99%t值获取方式Excel函数:=T.INV.2T(1-置信度, 自由度)标准差用法注意使用 STDEV.S()(样本标准差)样本量越大CI 越窄,更具代表性是否正态分布?正态分布假设通常默认成立,n≥6时基本接受检查通过标准CI 是否全部落在设定接受范围内(如98%–102%)
白衣少年wst 发表于 2025-7-29 15:39
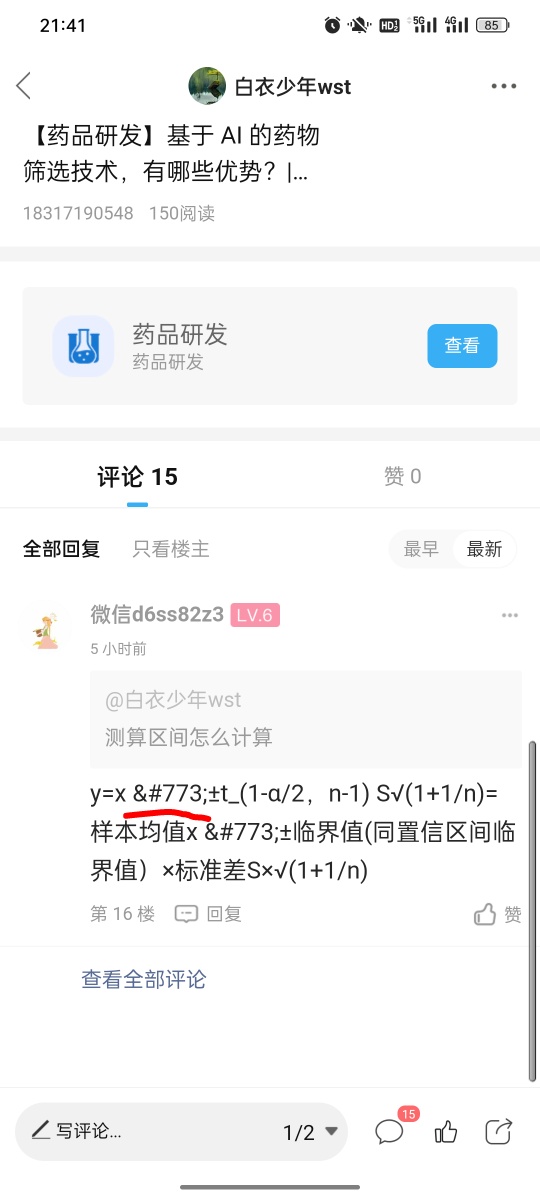
测算区间怎么计算
微信d6ss82z3 发表于 2025-07-29 16:30
y=x ̅±t_(1-α/2,n-1) S√(1+1/n)=样本均值x ̅±临界值(同置信区间临界值)×标准差S×√(1+1/n)

白衣少年wst 发表于 2025-7-29 15:40
好的,谢谢您
世间始终你好 发表于 2025-7-29 08:45
2025年版《中国药典》四部(特别是附录)关于分析方法验证中的置信区间(Confidence Interval, CI),主要 ...
世间始终你好 发表于 2025-7-29 08:45
2025年版《中国药典》四部(特别是附录)关于分析方法验证中的置信区间(Confidence Interval, CI),主要 ...
小麻花1 发表于 2025-8-23 16:11
这个可接受范围怎么定呢?
微信d6ss82z3 发表于 2025-7-30 08:43
补上,预测区间
世间始终你好 发表于 2025-7-29 08:45
2025年版《中国药典》四部(特别是附录)关于分析方法验证中的置信区间(Confidence Interval, CI),主要 ...
小麻花1 发表于 2025-8-23 16:11
这个可接受范围怎么定呢?
晨曦q8v 发表于 2025-10-28 14:18
您好,请问“评估样品回收率是否在预设接受范围内”,预设范围如何确定呢
预设接受范围(准确度):本方法用于产品释放检验(主成分含量测定),产品规格为 100% ± 5%。鉴于方法用于放行判断,预设方法准确度接受范围取 95% 置信区间应完全位于 95–105%(即规格范围);并采用风险分配原则,方法贡献不得超过规格半宽度的 50%(即 (k=0.5),允许方法偏差与随机误差之和 ≤ 2.5%)。验证样本量 n=6(每水平),置信水平 95%。若未达到上述要求,将评估方法改进或重新设定 acceptance criteria 并记录理由。
鑫意盎然 发表于 2025-10-24 15:31
请问药典中还有一个双侧预测区间的计算,哪个是什么情况下会用?做方法验证的时候应该用哪一个?
| 欢迎光临 蒲公英 - 制药技术的传播者 GMP理论的实践者 (https://www.ouryao.com/) | Powered by Discuz! X3.4 |